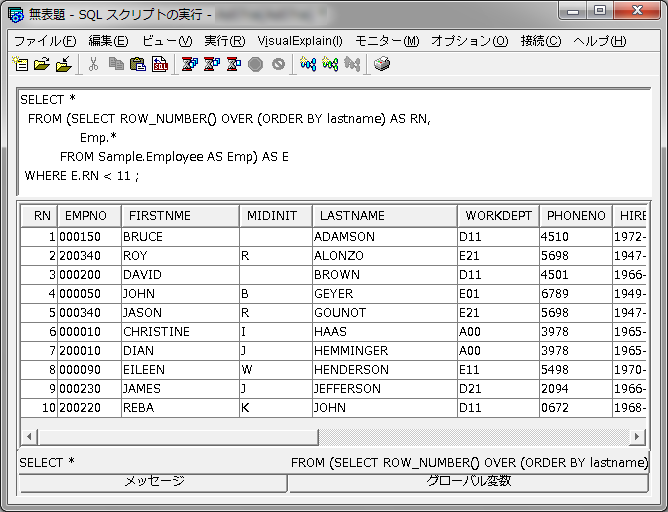
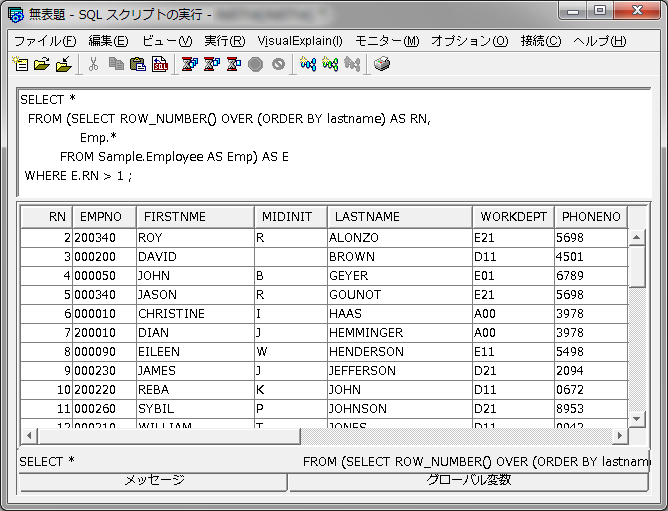
前回、ROWNUM 擬似列は標準 SQL の ROW_NUMBER で書き換えられる、ということをご紹介しました、
ROW_NUMBER の場合、副照会や WITH 句などを使ってあらかじめ行を順序づけしておく必要があるわけですが、もうちょっと手軽に「既存の SQL のままで、ただ最初の部分を n 行だけほしい」なんてときもあるでしょう。
たとえば、ROWNUM 擬似列の典型的な使い方である ↓ のような例ですね。
SELECT * FROM employees WHERE ROWNUM < 10;
↑ の
SELECT * FROM employees
のところがどんな SQL だったとしても、とりあえず最後に
ROWNUM < 10
と条件をつけると、最初の 10件が得られる、といったことがしたい場合、ありますよね。
Oracle の場合は、前回紹介したように、そんな単純にはいかないのですが、DB2 ファミリーではこれがカンタンにできるようになっています。
↓ のように、最後に FETCH FIRST n ROWS ONLY とつければいいんですね。
SELECT * FROM Sample.Employee FETCH FIRST 9 ROWS ONLY
英語そのままの、「最初の n 行のみを取ってくる」わけです。
くりかえしになりますが、Oracle で ROWNUM 擬似列を使う場合には ↓ のような考慮点があります。
「結果は、行がアクセスされる方法によって異なります。
たとえば、ORDER BY句の指定によってOracleが索引を使用してデータにアクセスする場合、索引なしの場合とは異なる順序で行が取り出されることがあります。
このため、次の文では、前述の例と同じ行が戻されるとはかぎりません。」
DB2 の場合にはそんなことを気にすることはありません。ごく自然に ORDER BY をつけてしまってかまいません。
SELECT * FROM Sample.Employee ORDER BY lastname FETCH FIRST 9 ROWS ONLY
DB2 for IBM i 7.1 での実行例です。
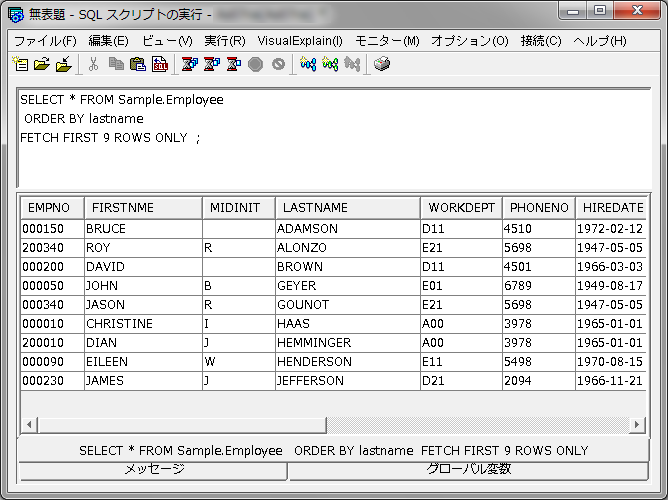
残念ながら、この FETCH FIRST n ROWS ONLY は標準SQL ではありません。DB2 ファミリー固有の構文です。(と思っていたのですが、実はそうではありませんでした → 「FETCH FIRST n ROWS ONLY が Oracle 12c で使えるようになっていますね!!」 2013/7/5 追記)
こういうちょっとした”小技”的なものは各データベースで固有の構文として実現されていることが多いですね。
時々、「Oracle の ROWNUM ではカンタンに行数制限ができるのに DB2 ではやり方がわからない」という質問をもらうことがあるのですが、けっこうこういうシンプルな解決策があったりします。(クドいようですが、、前回紹介したように Oracle でも「カンタン」ではありません…)
もちろん、標準SQLだったら ROW_NUMBER が使えますね。機能は ROW_NUMBER をはじめとする「OLAP 関数」の方がはるかに豊富です。
昔は各個別の製品で”便利な機能”を競っていて、そうしたものを使って「手軽に」「短く(コードの行数だったり期間だったり)」プログラムを作ることが優先される傾向がありました。
しかし、そうしたことで各製品間でポータビリティが下がってしまい、また、時間が経って、知っている人がいなくなったり、その製品でその機能がなくなったり、でいわば「世代間」の「ポータビリティ」が下がってしまい、長い目で見た場合は弊害の方が多いのでは?という意見も現在は多くなってきました。
思えば、昔は PC の OS が各メーカーで固有だったり、ネットワークで接続するにもプロトコルが各メーカーで固有だったり、というのが、今はもう標準化されてそんなことを気にする必要はなくなりましたよね。
同じことがプログラミングの世界でも起きている、と考えていいでしょう。「標準」に準拠して、”うまい””短い”やり方ではなく、ていねいに、誤解のないように書く、ということが優先されるようになってきています。
そうした観点では、やはり原則としては ROWNUM/FETCH FIRST n ROWS ONLY ではなく、ROW_NUMBER をはじめとする OLAP 関数を使ったほうがいいと思います。
機能が豊富なのはもとより、理解できる人も多くいるわけで、それだけプログラムの寿命も延びるわけです。
ただ、杓子定規に原則をあてはめるのではなく、状況を判断しながら ROWNUM や FETCH FIRST n ROWS ONLY なども使えるときは使えばいいのではないでしょうか。